Distributed Systems
This is intended to be my personal learning guide about the distributed systems, specifically being used in field of Analytics. I will try to cover Hadoop, Spark, mapreduce, Colossus, Presto SQL, HIVE, YARN and more along the way.
Topics to cover
Presto SQL
Designed to handle high number of concurrent queries on petabytes of data and was designed to scale up to exabytes of data. Presto was able to achieve this level of scalability by completely separating analytical compute(which process query) from data storage(HDFS). Presto architecture is distributed, supports massively parallel processing, does cost-based optimization, and processes analytics in memory.
How it works?
- Coordinater node analyze and generate an optimized query using cost-based optimizer and divided into tasks to be distributed across compute node.
- Compute nodes fetch only the necessary data from the storage layer, perform computations, and return the results to the coordinator node. Data is accessed through connectors, cached for performance, and analyzed across a series of servers in a cluster.
- The coordinator node aggregates the results from all the compute nodes and returns the final result to the user.
How it scales?
Presto’s cost-based query optimizer contributes significantly to both performance and scalability with advanced technology like join enumeration, where the join order is optimized, or join distribution selection, where workloads are either broadcast to multiple servers or partitioned for optimal performance.
Presto also applies dynamic filtering that can significantly improve the performance of queries with selective joins by avoiding reading data that would be filtered by join conditions.
Presto@Uber [Case Study]
- Automating cluster management to make it simple to keep up and running.
- A proxy server and placed it between Presto and the data, enabled them to automate query routing and isolate workloads based on priority.
- Workload management: Traffic is well isolated, batching queries based on speed and accuracy; Untested queries are routed to sample datasets.
- Granular permission down to the storage layer via user credentials.
- Most of Uber’s ETL jobs run on Apache Spark, however there are many ETL jobs in which Presto provides sufficient performance for quick execution (which are not resource intensive).
- Uber stores data into data stores including HDFS, object storage, Apache Pinot, and MySQL.
- Uber runs Presto as a microservice on their infrastructure platform and moves transaction data from Kafka into Apache Pinot, a real-time distributed OLAP data store, used to deliver scalable, real-time analytics.
Limitations
- Single coordinator node is a bottleneck.
- Sometimes with multiple joins, Presto goes out of memory. [fix: deploy multiple clusters]
- Presto query optimizer assumes that the data is stored in a certain way with correct statistics, proper layering, and populated footers.
Colossus
- Successor to GFS(Google File system), Colossus is a clustered level file system(distributed?) built on D managed disk storage.
- Each file is divided in fixed 64 MB chunks, with each chunk having unique 64 bit UUID provided by master node.
- Contains multiple nodes with data replication (default of three times), whose replication is configurable based on demand.
- Master node only stores metadata of the chunks, mapping UUID to chunks and file to chunks and copy location and access info, snapshots etc.
- With Colossus, a single cluster is scalable to exabytes of storage and tens of thousands of machines.
- Colossus steers IO around these failures and does fast background recovery to provide highly durable and available storage.
- Uses a mix of disk and flash, providing unified abstraction layer on top of it. The hottest data(in high demand) is put on flash for more efficient serving and lower latency.
- Data is rebalanced and moved to larger capacity drives as it ages and becomes colder.
Google File System
- Master node leases(time based) permission to process under mutual exclusion principle.
- After a write op, the changes are not saved until all chunkservers acknowledge, thus guaranteeing the completion and atomicity of the operation.
- It supports Record Append which allows multiple clients to append data to the same file concurrently and atomicity is guaranteed.
What Colossus does it different from GFS?
- Essentialy a v2 to GFS.
- Colossus introduced a distributed metadata model that delivered a more scalable and highly available metadata subsystem
- Scalable metadata storage
Architecture
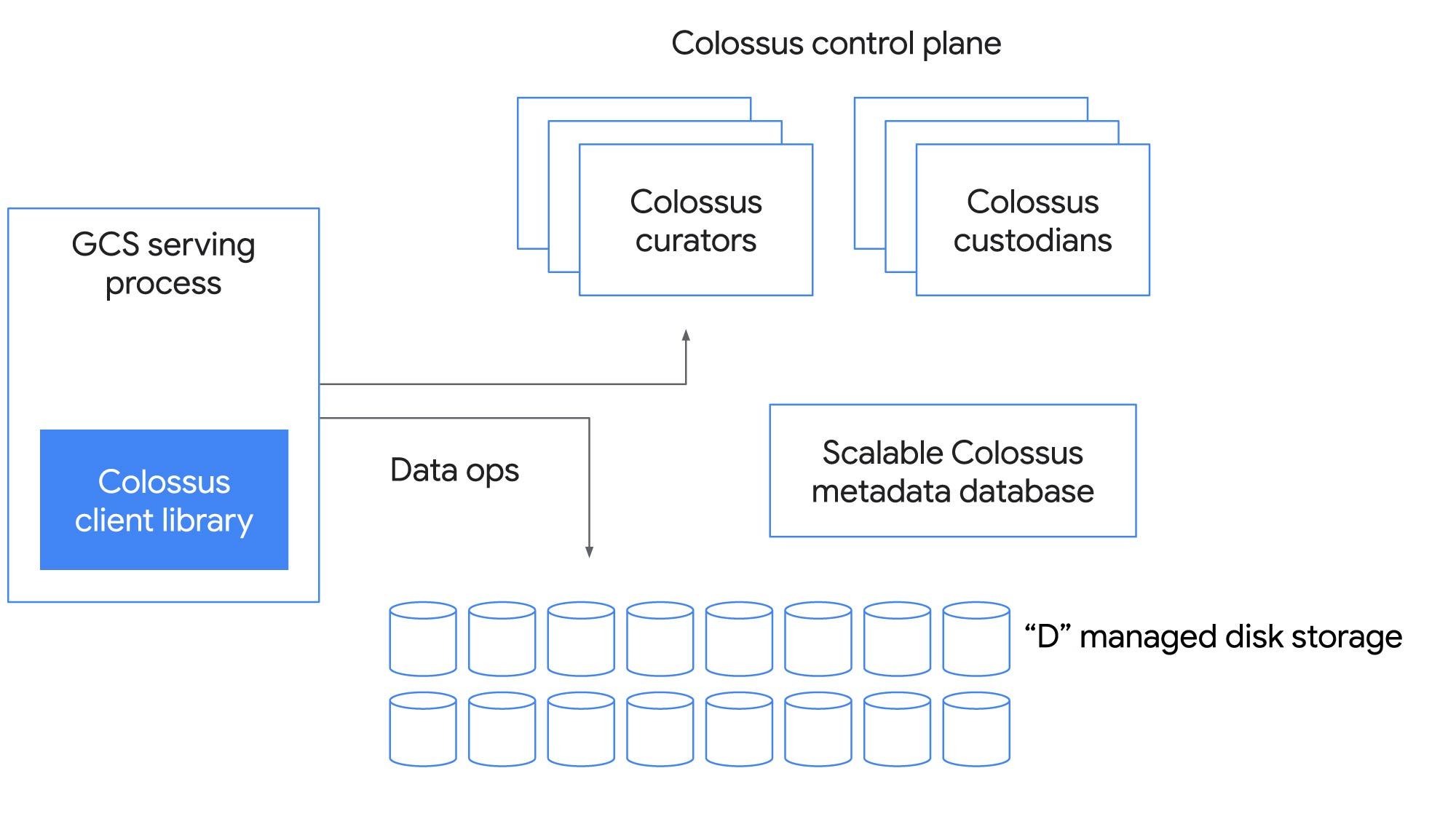
Components
- Client library
- Colossus Control Plane: Consists of multiple curators with client interact directly for control operations such as file creation, and can scale horizontally.
- Metadata database : Metadata is stored in BigTable by curators, which is high-performance NoSQL database.
- D File Server: Distributed File server, simple network attached disks.
- Custodians : For maintaining the durability and availability of data as well as overall efficiency, handling tasks like disk space balancing and RAID reconstruction.
MapReduce
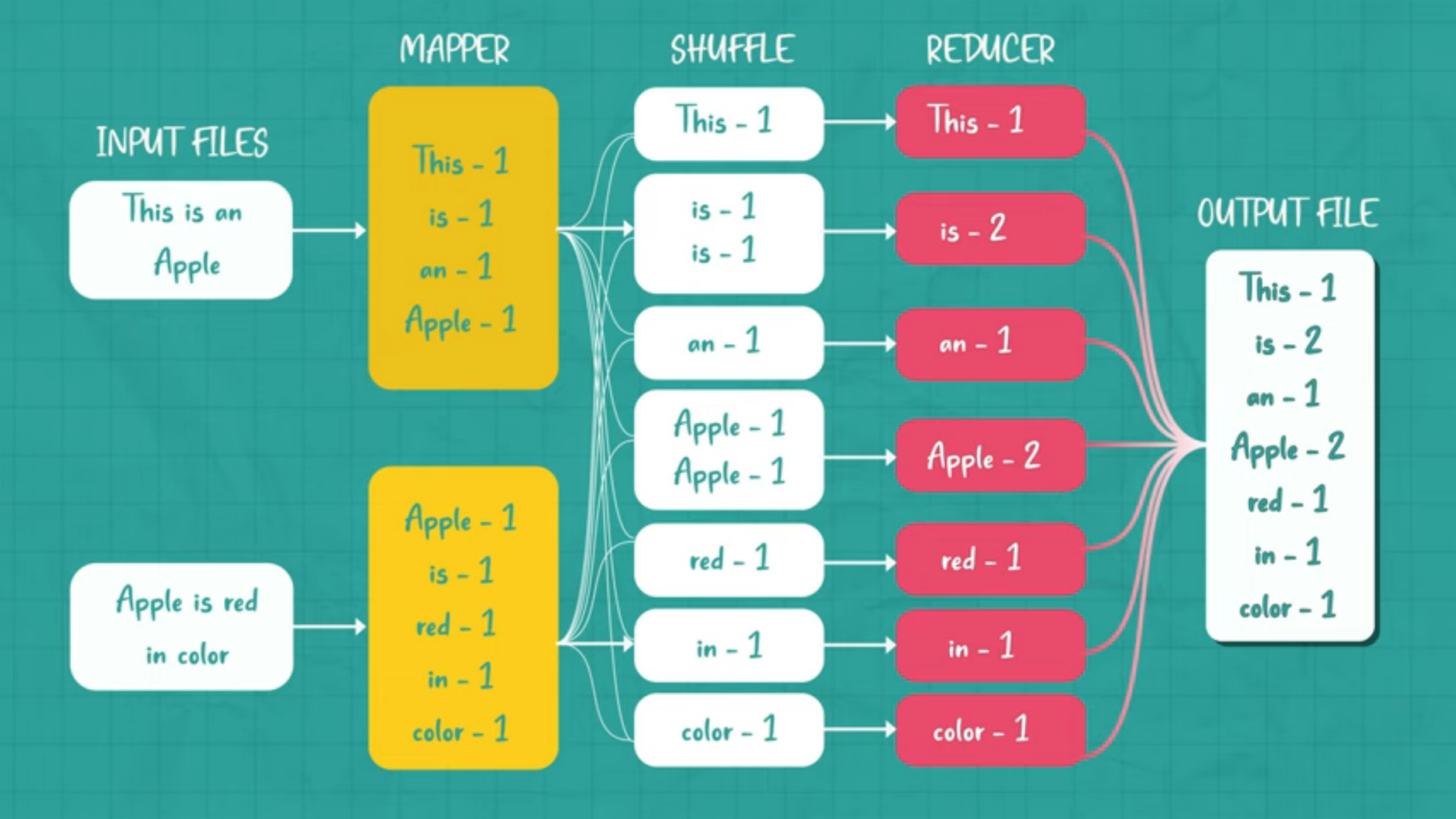 source: Video
source: Video
Built on top of Functional Programming, where each MapReduce task is stateless, i.e., each task has no sideeffect. In simple word f(x) is always the same y, irrespective of the situation.
Components of MapReduce Jobs
- Input: Multiple isolated data(s) (present on different worker nodes) on which query operation is to be performed.
- Map: A mapper is a (possibly randomized) user-defined function that takes as input one ordered 〈key; value〉 pair of binary strings. As output the mapper produces a finite multiset of new 〈key; value〉 pairs. Every compute tasks is done on respective worker node only.
- Shuffle: Worker nodes redistribute data based on the output keys (produced by the map function), such that all data belonging to one key is located on the same worker node.
- Reduce: A reducer is a (possibly randomized) user-defined function that takes as input a binary string k which is the key, and a sequence of values v1, v2, ... which are also binary strings. As output, the reducer produces a multiset of pairs of binary strings〈k; vk,1〉, 〈k; vk,2〉, 〈k; vk,3〉, .... The key in the output tuples is identical to the key in the input tuple. Each key is passed to a Reduce task on a worker instance.
More jargons
- emit(k, v): emits data as output in form of k/v pair from map/reduce function
- worker node: performs the map/reduce tasks
- master node: organize and segregate jobs into tasks, acts like a manager.
Dummy implementation
function map(String name, String document):
// name: document name
// document: document contents
for each word w in document:
emit (w, 1)
function reduce(String word, Iterator partialCounts):
// word: a word
// partialCounts: a list of aggregated partial counts
sum = 0
for each pc in partialCounts:
sum += pc
emit (word, sum)Apache Hadoop
INFO
Horizontal scaling: Add more independent resources to scale, all working as a single logical unit.
Vertical scaling: Change capacity of existing instances.
Hadoop makes horizontal scaling easy.
Uses parallel computing & distributed storage.
Works by distributing Hadoop big data and analytics jobs across nodes in a computing cluster, breaking them down into smaller workloads that can be run in parallel.
Hadoop Framework
- Hadoop distributed file system (HDFS): Distributed file system, where each Hadoop nodes operate on data that resides in their local storage.
- Yet Another Resource Negotiator (YARN):
Some Questions
- How is data consistency maintained in Horizontal scaling? Is data independent or inter-releated?
- Does scaling horizontally has its downtime like vertical scaling?
- Horizontal scaling CORS issue?
Good Reads
Presto SQL
Colossus
- https://cloud.google.com/blog/products/storage-data-transfer/a-peek-behind-colossus-googles-file-system
- https://research.google/pubs/the-google-file-system/
- https://en.wikipedia.org/wiki/Google_File_System#Design
- https://www.youtube.com/watch?v=q4WC_6SzBz4&t=500s
- https://www.systutorials.com/colossus-successor-to-google-file-system-gfs/
MapReduce
- MIT 6.824: Distributed Systems (Spring 2020)
- https://research.google/pubs/mapreduce-simplified-data-processing-on-large-clusters/
- Guide on Functional Programming
- https://theory.stanford.edu/~sergei/papers/soda10-mrc.pdf
- https://blogoscoped.com/archive/2008-01-24-n20.html
- https://stackoverflow.com/questions/388321/what-is-map-reduce
- Learn MapReduce with Playing Cards
- https://en.wikipedia.org/wiki/MapReduce
Hadoop
- https://cloud.google.com/learn/what-is-hadoop
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
- https://www.databricks.com/glossary/hadoop-cluster
- https://www.databricks.com/glossary/hadoop-distributed-file-system-hdfs
- https://www.databricks.com/glossary/hadoop
- https://www.oreilly.com/library/view/hadoop-the-definitive/9780596521974/
- https://www.oreilly.com/content/what-is-apache-hadoop/
Hive